DRIFT is an open-source online self-evolution policy optimization framework designed to enable continuous reasoning improvements in large language models without relying on external expert supervision.
Through the coordinated integration of dynamic difficulty routing, token-level rhythm gating, two-stage curriculum learning and robust experience replay, DRIFT creates a structured self-improving loop that ensures reliable and sustained policy improvement across diverse domains.
Overview
Achieving stable self-evolution in large language models without external expert supervision remains a central challenge in complex reasoning and scientific problem solving. Existing self-distillation and reinforcement learning methods often suffer from imprecise credit assignment, where coarse trajectory-level signals fail to distinguish the relative importance of different reasoning steps. Moreover, they typically treat model-generated trajectories as static supervision, without explicitly modeling learning progress or dynamically adjusting training strategies. As a result, they may over-optimize easy problems, provide insufficient guidance on hard problems, and inadequately explore boundary cases. To address these issues, we propose DRIFT, an online self-evolutionary framework for large language models post-training.
Our contributions are as follows:
- Dynamic Difficulty Routing. Historical pass rates are used as a stable estimate of the model's mastery level, enabling dynamic decisions on when to distill from past successful trajectories, when to explore new strategies, and when to reduce redundant training.
- Rhythm Gating Exploration. A structure-preserving exploration mechanism is introduced to encourage policy variation near the success boundary, while preserving useful reasoning patterns through token-level Rhythm Gating.
- Two-Stage Curriculum Learning. A two-stage curriculum strategy is designed to align training behaviors with different phases of model learning. The first stage focuses on rapid capability growth and success buffer accumulation, allowing the model to reach a stable performance plateau efficiently. The second stage shifts toward balanced exploration, correction, and convergence, enabling continuous and stable performance improvement.
- Experience Replay via Success Buffer. DRIFT incorporates a historical success buffer to reuse high-quality trajectories. It further adopts a curriculum learning strategy to support smooth model evolution and uses Rhythm Gating to provide structured exploration rewards on boundary problems.
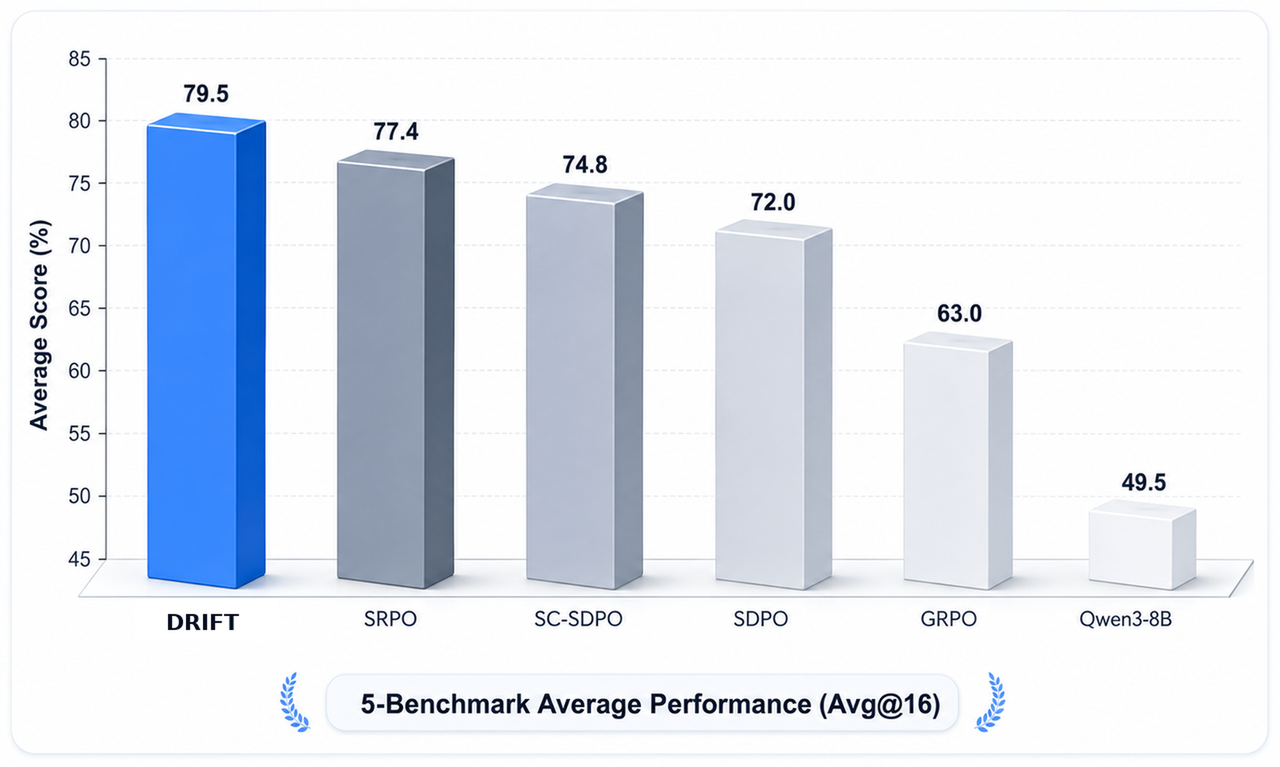
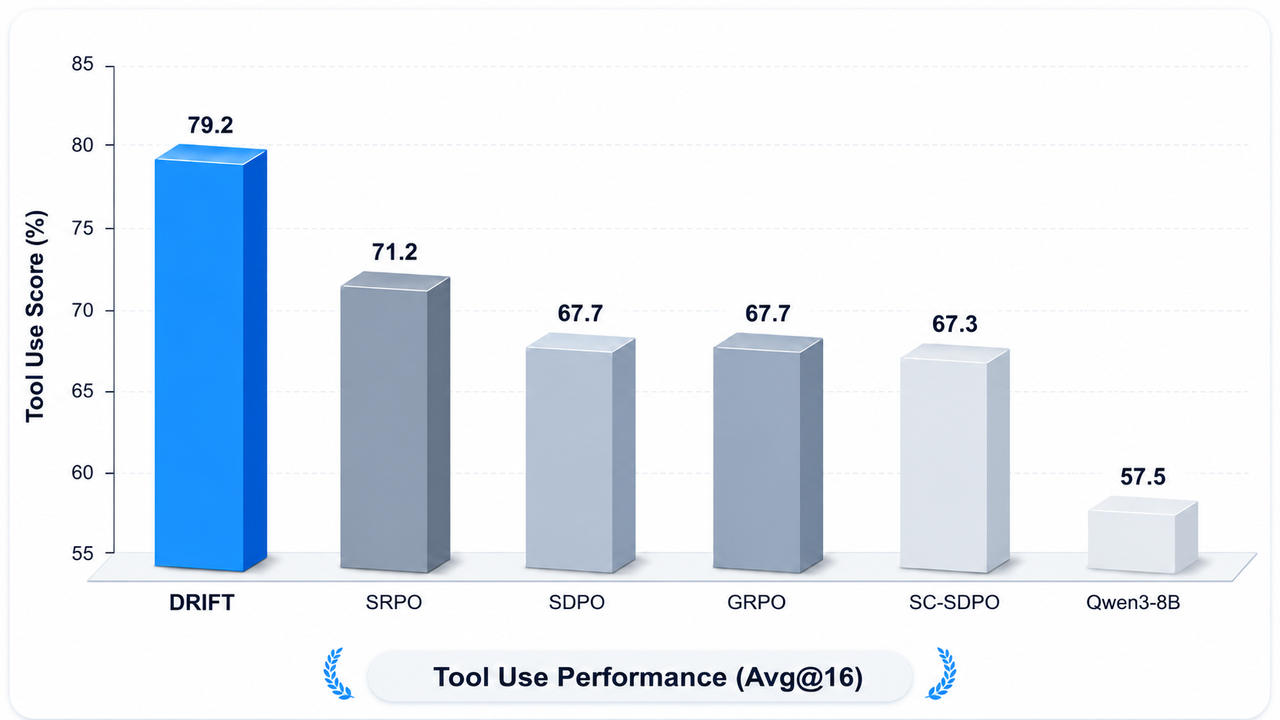
We evaluate DRIFT on diverse task categories, including biology, chemistry, materials science, physics, and tool use. Experimental results show that DRIFT significantly outperforms reproduced SDPO and GRPO baselines, and further improves upon recent methods such as SRPO, demonstrating stronger training stability and better cross-domain generalization.
Methodology
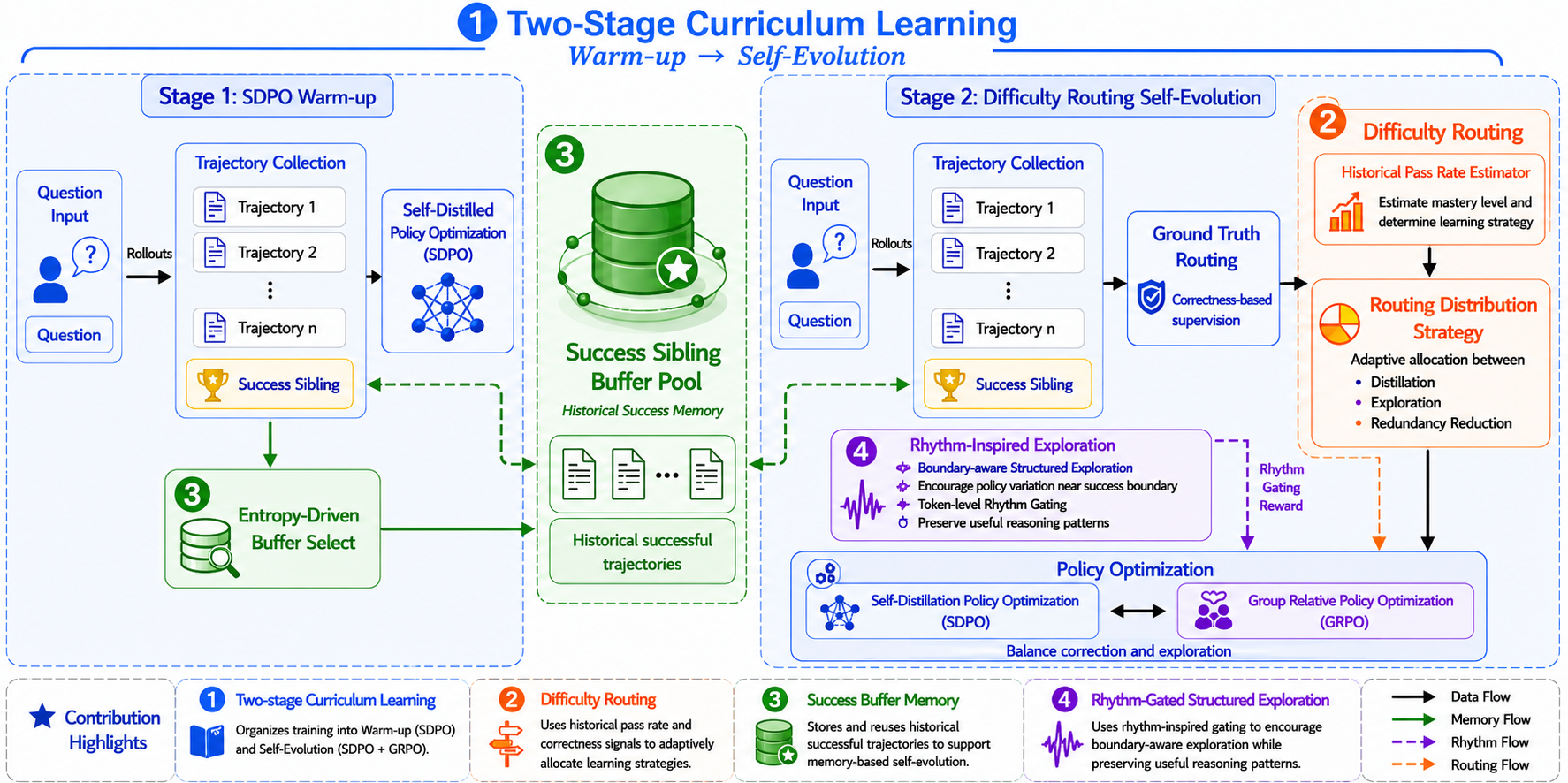
Training Framework for DRIFT. We integrate on-policy self-distillation and online reinforcement learning into a coherent self-evolution loop guided by a two-stage curriculum.
- Warmup via Entropy-Driven Self-Distillation. DRIFT uses entropy-driven self-distillation for efficient warmup. During this stage, the model continuously samples trajectories within the online training loop and performs self-distillation on its own successful rollouts. DRIFT prioritizes successful trajectories with the highest token-level sequence entropy as distillation targets. This approach rapidly enhances model capabilities with fewer rollouts while maintaining the diversity of initial exploration, mitigating premature distribution collapse, and quickly accumulating high-quality reasoning paths for the success buffer.
-
Self-Evolution via Routing.
Once the baseline performance reaches a stable plateau, DRIFT transitions into the second stage, namely the self-evolution stage. In this stage, online rollouts are dynamically routed according to their estimated pass-rate, allowing the framework to assign different training signals to problems at different difficulty levels. Failed rollouts bypass reinforcement learning updates and are instead corrected through online distillation from high-quality successful trajectories, either sampled from the parallel rollout group or retrieved from the success buffer. Successful rollouts, on the other hand, are routed to the online GRPO branch, where correct behaviors are further reinforced. This self-evolution process is jointly regulated by macro-level difficulty routing and micro-level token gating, enabling a balanced interaction between correction, exploration, and stable policy improvement.
- Macro-Level Difficulty Routing. At the macro-level, the dynamic difficulty routing system maintains an exponentially smoothed pass-rate for each problem to estimate the model's evolving mastery. It dynamically downweights the contribution of GRPO updates on easy tasks with homogeneous reward signals and on hard-to-solve tasks that are prone to accidental guessing, thereby focusing on the high-return medium-difficulty manifold.
- Micro-Level Rhythm Gating for Structured Exploration. At the micro-level, DRIFT introduces a structured rhythm gating exploration mechanism that maps sequence-level rewards into token-level modulation through an Anchor Rhythm Gate. By tracking relative entropy dynamics between the student and reference models, as well as directional entropy collapse, this gate amplifies policy updates only when a token both exhibits local improvement over the teacher model and corresponds to a critical structural anchor, such as a logical or causal node.
Mathematical Formulations
The overall hybrid training objective minimizes a difficulty routing combination of self-distillation on incorrect trajectories and GRPO with Rhythm Gating on correct trajectories:
where $\gamma_i$ is determined by difficulty routing.
Further details on the theoretical motivation, underlying insights, and mathematical demonstration will be provided in our upcoming paper.
Experimental Results
We evaluated DRIFT on five prominent, multi-turn reasoning and academic benchmarks. Across nearly all domains, DRIFT achieves consistent improvements:
| Method / Model | Biology | Chemistry | Materials | Physics | Tool Use | Average |
|---|---|---|---|---|---|---|
| Qwen3-8B | 30.8 | 41.2 | 58.9 | 59.2 | 57.5 | 49.5 |
| SDPO (Paper) | 56.8 | 80.9 | 78.4 | 75.6 | 68.5 | 72.0 |
| SDPO (Reproduced) | 64.8 | 78.9 | 76.1 | 72.7 | 67.7 | 72.0 |
| GRPO (Paper) | 59.9 | 74.5 | 77.1 | 72.7 | 65.7 | 70.0 |
| GRPO (Reproduced) | 47.4 | 65.6 | 73.5 | 60.6 | 67.7 | 63.0 |
| SRPO (Paper) | 72.8 | 83.0 | 81.5 | 78.4 | 71.2 | 77.4 |
| DistIL (Paper) | 66.6 | 80.8 | 76.2 | 80.8 | - | - |
| SC-SDPO (Paper) | 65.4 | 80.6 | 79.3 | 81.6 | 67.3 | 74.8 |
| PGPO (Paper) | 61.3 | 77.6 | 78.7 | 77.6 | - | - |
| DRIFT (Ours) | 74.4 | 82.0 | 81.4 | 80.5 | 79.2 | 79.5 |
BibTeX
@misc{beike2026drift,
title = {DRIFT: Difficulty Routing Self-Distillation with Rhythm Gating Exploration and Success Buffer Training},
author = {Haisen Luo and Yiwei Liu and Haoning Wang and Dan Liu and Junxi Yin and Haotian Wang and Lei Zhang and Xiaoyu Tian and Shuaiting Chen and Yuansheng Song and Baoyan Guo and Xiongfei Yan and Bolan Yang and Chengwei Liu and Ming Cui and Jiong Chen},
year = {2026},
eprint = {2606.30345},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://github.com/LianjiaTech/drift},
}